
|
Метод быстрой сортировки
"Быстрая сортировка", хоть и была разработана более 40 лет назад, является наиболее широко применяемым и одним их самых эффективных алгоритмов. Метод основан на подходе "разделяй-и-властвуй". Общая схема такова:
В конце получится полностью отсортированная последовательность. Рассмотрим алгоритм подробнее. Разделение массива На входе массив a[0]...a[N] и опорный элемент p, по которому будет производиться разделение.
Рассмотрим работу процедуры для массива a[0]...a[6] и опорного элемента p = a[3].
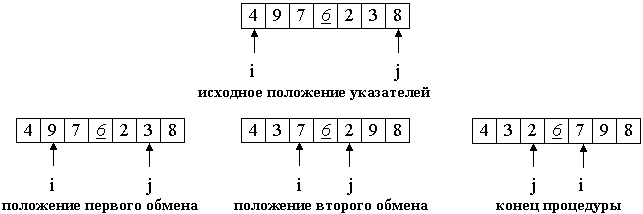 Теперь массив разделен на две части: все элементы левой меньше либо равны p, все элементы правой - больше, либо равны p. Разделение завершено. Общий алгоритм Псевдокод.
quickSort ( массив a, верхняя граница N ) {
Выбрать опорный элемент p - середину массива
Разделить массив по этому элементу
Если подмассив слева от p содержит более одного элемента,
вызвать quickSort для него.
Если подмассив справа от p содержит более одного элемента,
вызвать quickSort для него.
}
Реализация на Си.
template Каждое разделение требует, очевидно, Theta(n) операций. Количество шагов деления(глубина рекурсии) составляет приблизительно log n, если массив делится на более-менее равные части. Таким образом, общее быстродействие: O(n log n), что и имеет место на практике. Однако, возможен случай таких входных данных, на которых алгоритм будет работать за O(n2) операций. Такое происходит, если каждый раз в качестве центрального элемента выбирается максимум или минимум входной последовательности. Если данные взяты случайно, вероятность этого равна 2/n. И эта вероятность должна реализовываться на каждом шаге... Вообще говоря, малореальная ситуация. Метод неустойчив. Поведение довольно естественно, если учесть, что при частичной упорядоченности повышаются шансы разделения массива на более равные части. Сортировка использует дополнительную память, так как приблизительная глубина рекурсии составляет O(log n), а данные о рекурсивных подвызовах каждый раз добавляются в стек. Модификации кода и метода Из-за рекурсии и других "накладных расходов" Quicksort может оказаться не столь уж быстрой для коротких массивов. Поэтому, если в массиве меньше CUTOFF элементов (константа зависит от реализации, обычно равна от 3 до 40), вызывается сортировка вставками. Увеличение скорости может составлять до 15%. Для проведения метода в жизнь можно модифицировать функцию quickSortR, заменив последние 2 строки на
if ( j > CUTOFF ) quickSortR(a, j); if ( N > i + CUTOFF ) quickSortR(a+i, N-i); Таким образом, массивы из CUTOFF элементов и меньше досортировываться не будут, и в конце работы quickSortR() массив разделится на последовательные части из <=CUTOFF элементов, отсортированные друг относительно друга. Близкие элементы имеют близкие позиции, поэтому, аналогично сортировке Шелла, вызывается insertSort(), которая доводит процесс до конца.
template В случае явной рекурсии, как в программе выше, в стеке сохраняются не только границы подмассивов, но и ряд совершенно ненужных параметров, таких как локальные переменные. Если эмулировать стек программно, его размер можно уменьшить в несколько раз. Чем на более равные части будет делиться массив - тем лучше. Потому в качестве опорного целесообразно брать средний из трех, а если массив достаточно велик - то из девяти произвольных элементов. Пусть входные последовательности очень плохи для алгоритма. Например, их специально подбирают, чтобы средний элемент оказывался каждый раз минимумом. Как сделать QuickSort устойчивой к такому "саботажу" ? Очень просто - выбирать в качестве опорного случайный элемент входного массива. Тогда любые неприятные закономерности во входном потоке будут нейтрализованы. Другой вариант - переставить перед сортировкой элементы массива случайным образом. Быструю сортировку можно использовать и для двусвязных списков. Единственная проблема при этом - отсутствие непосредственного доступа к случайному элементу. Так что в качестве опорного приходится выбирать первый элемент, и либо надеяться на хорошие исходные данные, либо случайным образом переставить элементы перед сортировкой. Рассмотрим наихудший случай, когда случайно выбираемые опорные элементы оказались очень плохими(близкими к экстремумам). Вероятность этого чрезвычайно мала, уже при n = 1024 она меньше 2-50, так что интерес скорее теоретический, нежели практический. Однако, поведение "быстрой сортировки" является "эталоном" для аналогично реализованных алгоритмов типа "разделяй-и-властвуй". Не везде можно свести вероятность худшего случая практически к нулю, поэтому такая ситуация заслуживает изучения. Пусть, для определенности, каждый раз выбирается наименьший элемент amin . Тогда процедура разделения переместит этот элемент в начало массива и на следующий уровень рекурсии отправятся две части: одна из единственного элемента amin, другая содержит остальные n-1 элемента массива. Затем процесс повторится для части из (n-1) элементов.. И так далее.. При использовании рекурсивного кода, подобного написанному выше, это будет означать n вложенных рекурсивных вызовов функции quickSort. Каждый рекурсивный вызов означает сохранение информации о текущем положении дел. Таким образом, сортировка требует O(n) дополнительной памяти.. И не где-нибудь, а в стеке. При достаточно большом n такое требование может привести к непредсказуемым последствиям. Для исключения подобной ситуации можно заменить рекурсию на итерации, реализовав стек на основе массива. Процедура разделения будет выполняться в виде цикла. Каждый раз, когда массив делится на две части, в стек будет направляться запрос на сортировку большей из них, а меньшая будет обрабатываться на следующей итерации. Запросы будут выбираться из стека по мере освобождения процедуры разделения от текущих задач. Сортировка заканчивает свою работу, когда запросы кончаются. Псевдокод Итеративная QuickSort (массив a, размер size) { Положить в стек запрос на сортировку массива от 0 до size-1.
do {
Взять границы lb и ub текущего массива из стека.
do {
1. Произвести операцию разделения над текущим массивом a[lb..ub].
2. Отправить границы большей из получившихся частей в стек.
3. Передвинуть границы ub, lb чтобы они указывали на меньшую часть.
} пока меньшая часть состоит из двух или более элементов
} пока в стеке есть запросы
}
Реализация на Си.
#define MAXSTACK 2048 // максимальный размер стека template Размер стека при такой реализации всегда имеет порядок O(log n), так что указанного в MAXSTACK значения хватает с лихвой. |
Автор проекта: USU Software
Вы можете выкупить этот проект.